MORE FREE TERM PAPERS MANAGEMENT:
|
||||||||||||||||||||||||||
Managing Distributed Projects
In today’s organizations the common unit of work is the project. Turner defines a project as “an endeavor in which human, material, and financial resources are organized in a novel way, to undertake a unique scope of work, for a given specification, within constraints of cost and time, so as to achieve beneficial changes defined by quantitative and qualitative objectives”. Projects have moved from being simple phenomena to manage to more complex entities spanning geographical locations, multiple occurrences, and different organizational affiliations, with IT being the key enabler for the transformation. For instance, a co-located program involves multiple projects running at one location, whereas a distributed project is a single endeavor conducted from multiple locations. Finally, the most complicated scenario is multiple projects conducted at multiple locations.
Complexities can be attributed to managing multiple interdependencies across time, space, and projects Knowledge in projects calls for a close look at insights generated within each individual project, such as schedules, milestones, meeting minutes, and training manuals. Individual project members need to know when, what, how, where, and why something is being done and by whom, with the goal being to promote efficient and effective coordination of activities. From the macro perspective, an organization must have an inventory of all projects under way at any given time, or knowledge about projects. This aids in the planning and controlling of resources to maximize utilities. Knowledge includes employee assignments to projects, return on investment, cost and benefit analysis, deadlines, and customer commitments and expectations. It is common for such knowledge to be generated at regular intervals, such as in weekly, monthly, or bi-monthly reports. Knowledge from projects is a post hoc analysis and audit of key insights generated from carrying out projects. This knowledge is a key determinant of future project success, as it aids organizational learning. These three categories call for distinct roles by IT to enable effective and efficient knowledge management.
Communication Is Key
Despite their geographic separation; distributed developers need to stay in constant contact. Conference calls and email are basic and important ways that should be used regularly. Even when time zone differences require some team members to participate during unusual hours, there is still no substitute for talking to each other.
However, today the networked team has some new choices to consider as well:
Threaded Discussions: Many software tools facilitate newsgroup-like discussions that allow multiple developers to communicate asynchronously on any topic. Better than email, threaded discussion tools focus debates on specific issues and save the dialog for later use. Some tools can link discussions to specific projects, tasks, or other development assets.
Instant Messaging: IM is starting to find its way into the business world as a valuable tool. Lower friction than the telephone, yet more interactive than email, IM is valuable for asking a quick question or holding an informal chat. Like threaded discussions, many IM tools can save dialogs for later review. To avoid privacy concerns of IM messages traversing public networks, teams should consider an IM tool that can be deployed on the corporate intranet.
Blogging: Web logging or "blogging" is the process of instant publishing to a Web page. "Blogs" typically contain short messages that follow a chronological order. Blogging was created by individuals wishing to chronicle daily work, personal experiences, or just random streams of consciousness. Like IM, blogging is beginning to find its way into the corporate setting. Team members can use blogging to publish their progress, and the Web interface makes it easy for everyone to see each other’s notes.
Web Conferencing: When real-time communication is needed, conference calls can be significantly enhanced with Web conferencing. Web conferencing can be used for group presentations, interactive planning and review, and even unstructured brainstorming sessions. Both pay-for-use Web conference services and commercial software products that can be centrally installed are available. Depending on the software, Web conferencing products may include collaboration features such as white boarding, file sharing, instant messaging, and cooperative editing.
Depending on bandwidth availability, teams may also want to consider emerging technologies such as voice-over-IP and even video-over-IP. Anything that promotes effective team communication should be considered.
Shared Repositories
In typical projects, developers must share many of the assets used to specify, design, implement, and test software. In the past, network bandwidth and even the tools themselves prevented remote developers from having direct access to the same repositories used by developers operating behind the corporate firewall. Today, a broad array of software management tools is Internet-enabled. Combined with better availability of reliable bandwidth, these tools increasingly make it feasible for all team members to share common repositories.
Shared repositories provide developers with up-to-date information, thereby reducing conflicts. Internet-enabled, repository-centric tools are available for key development processes such as
• Requirements Management: formal requirement specifications, dependencies, responsibilities, and change history
• Source Code Management: versioned file assets such as design documents, source code, and binary files
• Change Management: bug reports, new feature requests, defect tracking, and traceability
• Project Management: Project schedules, task breakdowns, work assignments, and progress reports
• Test Management: Test plans, test cases, and test results
Moreover, some Internet-enabled tools that help to manage these processes are starting to provide integrated collaborative features, such as threaded discussions and peer-to-peer messaging. These tools further foster team synchronization.
Large projects and large project teams may require access to many corporate resources. In these scenarios, teams can benefit from resource portals that consolidate and concentrate disparate information sources. For example, Web-based Development Resource Portals (DRPs) can provide access to research materials and project information from multiple repositories, focused on the needs of developers. Integrated search and discovery capabilities provide a central place to traverse a broad array of information. For effective distributed development, the key is to surface information stored in corporate repositories to all members of the team.
Keep Remote Developers Involved
Perhaps the most important way to keep remote developers on track is to keep them included. Every team member needs periodic reassurance that they are important to the project. The more a remote developer feels in the loop, the more likely they are to contribute effectively. There are many ways to ensure that distant team members are on track while fostering their sense of involvement. Here are a few ideas:
Show-and-Tell: Remote team members should periodically demonstrate their work via online presentations. They should also be included in training sessions, turnover meetings, and even customer presentations. Participation in important milestones such as these allows distant developers to showcase their work and demonstrate their expertise.
Reviews: Periodic design and code reviews are good ways to keep tabs on remote developers’ progress. In order to keep them from feeling singled out, they should participate in reviews of other team members’ work as well. One approach is to perform code walkthroughs, in which the author drives the presentation. This approach rotates each team member’s responsibilities and maintains a sense of equality.
On-Site Visits: Teams shouldn’t forget the importance of periodically inviting remote developers to headquarters or other development centers. Conversely, most remote developers appreciate having occasional team meetings at their locale. Digital collaboration and information sharing is helpful, but nothing can replace the interaction and camaraderie of occasional face-to-face meetings.A close examination of the codification and personalization approaches led us to draw parallels to two popular models of computing: client-server and peer to peer (P2P). The client-server paradigm, wherein a centrally located resource is used by multiple clients to request services for task accomplishment, is common in most distributed computing environments. P2P is a rather recent computing paradigm in which all nodes can take the role of either client or server. A node can request information from any other node, or peer, on the network and also serve content. Due to the centralization of the main resource provider, client server computing is similar to the codification strategy, whereas the distributed nature of P2P, in which each node owns and makes its resources available to the network, can be viewed as parallel to the personalization strategy. Hence, we term codification and personalization as the centralized and the P2P approaches, respectively, to knowledge management.
Managing Distributed Testing
There's a great deal talked about different types of testing: Web testing, regression is testing, user testing and of course black box testing, white box testing, even gray box testing. But there is another type of testing that receives less coverage, distributed testing. Here I shall attempt to explain what we mean by distributed testing, and how it compares with non-distributed testing.
With TET where the terminology is very important. Running tests on several machines at once is called remote testing, and remote testing is non-distributed.
Non-distributed Testing
So, let's start with non-distributed testing. It is more frequently used. Non-distributed tests are those that run on a single computer system and do not, normally, involve any form of interaction with other computer systems.
I say not, normally, because there are some tests that are run from a host machine to test a target device that is running a real-time or embedded operating system. These tests can be configured and run as non-distributed tests. But the testing of real-time and embedded systems is a subject in it, and will be the subject of another article.
To make it even more complicated, we can divide non-distributed tests into two further categories: local and remote testing.
Local testing involves running test cases on a local computer system. So I might run a local test on my laptop, wherever I am. I don't need to be on a network to run a local test. By comparison remote testing does require that I have a network connection. It allows me to use this connection to run a test on another computer system. This is very useful as it allows me to run tests on other processors on the network without leaving my desk, and to collect the results back at my desk. I might run remote tests on several machines, concurrently, (let's call this Simultaneous testing) within one test suite, and collect all of the results back at my desk.
With simultaneous testing, even when I'm running tests on many machines at once, those tests do not involve any interaction between the different processors or the tests that they are running.Distributed Testing
Distributed testing is different. Because a distributed test case consists of two or more parts that interact with each other. Each part being processed on a different system. It is the interaction between the different test case components that sets distributed testing apart. Typically it is this interaction between different computer systems that is under test. For example, testing a client-server application or the mounting of a file system. All of the test cases processed on all of the different processors contribute towards a single, common, result.
This is not the same as simultaneous testing. Because even though simultaneous testing involves different test case components being carried out on different processors, and contributing towards a single result, there is no interaction between the test cases or the processors. As noted above it is this interaction that sets distributed testing apart.
A further challenge that we have to face with distributed testing is that of platform. For example testing a client server application may involve using a Windows client to access one or more UNIX servers, and controlling the whole process from a Linux desktop. So our environment has to be written at a level capable of working across all of these platforms.
Test Scenarios
Once we have set up our hardware environment and established our network connections between the different systems we need to describe the way in which we want to carry out our test cases. We can do this in a test scenario. This lists all of the test cases and describes how they are to be processed. The description is provided in the form of a directive. For the serial processing of test cases on a local machine we don't need any directives, just a list of test cases in the order that they are to be processed. But the test scenario adds a powerful capability to describe tests that, for example, should be repeated a number of times or for a period of time.
For remote or distributed testing we use remote or distributed directives which define which systems will run which parts of the test case. Other directives allow us, for example, to run a number of tests in parallel. The power of the directives is further enhanced as we can nest them one inside the other. So, for example, we can use parallel and remote directives to do simultaneous testing, with different tests being carried out on different systems at the same time.The distributed directive is used to define distributed tests, and the scenario file that contains the directive is reads by a Controller (see Figure), which allocates the different parts of the tests to separate control services. One for the local system (the control console), and one for each remote system. Note that these are logical systems and that more than one logical system can be resident on the same physical device. A test suite may comprise many (up to 999) remote systems all of which interact and contribute towards a single test result. We feed in one scenario file and get out one results file.
Figure 1: Simple Architecture Diagram for Distributed TestingSynchronization
Ensuring that all of the tests happen on all of the systems in the correct order is the greatest challenge in distributed testing. To do this we synchronize the test cases either automatically, at system determined points (e.g. the start and end of each test case), or at user determined points. Synchronization is the key to distributed testing and is important enough to merit separate consideration. (more . . . )
The challenge of distributed testing lies both in synchronization and the administration of the test process: Configuring the remote systems; generating the scenario files; and processing the results to produce meaningful reports. Being able to repeat the tests consistently, and to select tests for repetition by result i.e. regression testing. And doing this repeatedly and across many different platforms, UNIX, Windows and Linux.Here, we look at the implications of these approaches on the aggregation, transfer, and sense making of knowledge in non-collocated work environments. Drawing on the strengths and limitations of each technique, we propose a hybrid model. We begin by comparing the approaches, focusing on three dimensions: sharing, control of, and structuring of knowledge.
SharingMany studies report that members of organizations fear that sharing their knowledge with the community at large makes them less valuable to the organization. As such, the idea of contributing to a central repository does not jibe well. In the centralized approach, there are inherent delays between the moments the knowledge is created in the minds of individuals and when it is posted to the repository. Individuals may delay posting not only for gate keeping purposes but also to allow for confirmation of events, sometimes to the point of irrelevance. This defeats the concept of real-time availability of knowledge, as insights not captured immediately are lost. As individuals are more likely to store the draft notes and working documents of insights on their local repositories than on the main server, this concern is minimized in the P2P approach. Moreover, the P2P approach fosters dialogue among the various agents of the team and develops a spirit of community, as each agent interacts with peers to gain knowledge. Hence socialization and externalization is mandated, which is pivotal for tacit knowledge exchange .
Control
The centralized approach detaches the contributor from his or her knowledge. Once posted centrally, the author loses control over knowledge access and usage. In the P2P approach, each member of the organization retains his or her knowledge, as well as explicit control over its visibility.
Members are connected to their peers in the organization and can choose what knowledge to share. Since individuals have control over their own knowledge repositories, they are less likely to view sharing of knowledge as a threat to their value.Structuring
Knowledge contained in the central repository is structured on such dimensions as teams, products, and divisions, enabling faster access times to required elements. This facilitates the use of filtering and categorizing mechanisms for sifting. However, the nature of centrality calls for global filtering and categorizing schemas, which are not optimal in all cases. Setting global thresholds for relevance, accuracy, and other attributes for knowledge may lead to loss of knowledge, as insights considered important for one project may be lost due to filters. The significant costs in categorizing information by appending appropriate key words and metadata to knowledge prior to posting it are borne by everyone, whereas the benefits of better retrieval times are selectively reaped
These characteristics. Also make the centralized approach useful for storing structured knowledge about and from projects. Requirements for knowledge about projects do not change frequently. As such, having structured approaches for retrieval is facilitated via a centralized approach. But only a small percentage of the organization uses knowledge about projects for budget preparation, staff allocation, and other control purposes. Hence, storing such knowledge in a central repository is of minimal value to the remaining employees, or the majority of the organization. However, the P2P approach is not advisable here due to difficulties in filtering, categorization, and coordination of disparate knowledge sources.
Using the centralized approach to store knowledge from projects helps make lessons learned from past endeavors available to organizational members at large, but centralization is no panacea. Once again it may be difficult to contribute knowledge if appropriate categories do not exist or the repository is not amenable to customization. As the repository is built on the premise that all members of the organization need to access the knowledge base, care is taken to provide a shared context. This entails knowledge contributors making extra effort to ensure their thoughts and insights can be understood by their peers once entered into the knowledge repository. Developing a ranking mechanism to indicate the relevance of results becomes easier owing to the structured categorization of knowledge and the shared context. Thus, transfer of knowledge from the provider to the consumer is improved by the centralized approach.
John Deere, a global producer of tractors and other equipment, uses the personalization approach to knowledge management. Deere has established communities of practice (CoPs) for facilitating knowledge exchange. It has recognized hundreds of CoPs, approximately 65 of which use JD Mind Share as a technology solution. Knowledge is exchanged within these CoPs via videoconferencing, email, and discussion groups. Using the personalization approach, Deere has experienced the challenges discussed in this article, including the difficulty of sharing knowledge among CoPs due to lack of shared context and varying schemas of knowledge representation.A Hybrid Approach
To gain the benefits of the centralized and P2P approaches and overcome their limitations, we propose a hybrid model with two components. At the core of the system is the first component: a central repository holding popular knowledge (knowledge about and from projects). This repository serves as an index to the second component: knowledge available by peers (knowledge in projects). By storing knowledge about and from projects in a central repository, we ensure the following:
• Maintenance of a shared context, thus improving means of exploration of knowledge;
• Ease of access, as knowledge about projects is well structured and stored in a central repository;
• Ease of transfer of knowledge from projects throughout the organization;
• Enhanced validity of knowledge from projects, since only validated knowledge makes its way to central storage. Members whose knowledge is stored centrally can also be rewarded for its high value; and
• Easy identification of the source of knowledge about and from projects.A centrally located index for knowledge in projects, the second component of the central repository, helps foster an efficient coordination mechanism, as this index contains the sources of knowledge in projects. It can serve as the knowledge dictionary to integrate individual knowledge. Common terms and categories can be assigned, along with facilities to serve as an organizational thesaurus. We assert that knowledge in projects must be exchanged via P2P approaches. Knowledge capture becomes efficient and effective, as each project team can set up its own protocols, build categories, and develop filtering mechanisms. As each project is unique and each team is different, allowing for the establishment of flexible knowledge creation and exchange protocols is pivotal. Such an approach prevents the loss of knowledge considered relevant to one project, site, or stakeholder, since local parameters will not affect the global knowledge of the organization.
Moreover, it promotes efficient sharing of knowledge among team members, as the fear of making one’s insights available throughout the organization is absent. If an employee is interested in a knowledge object dealing with an ongoing project, he or she can refer to the index and obtain the source. The employee can then request that knowledge directly from the source.
Furthermore, maintenance of local repositories becomes simple, as each team is given the right to purge their local repositories periodically, therefore deciding which knowledge is relevant and useful and which is not. This not only prevents irrelevant and outdated search results, but also helps improve access times. It also helps circumvent the version control problem by constantly updating the repository while purging old and irrelevant knowledge.Motorola, a major provider of wireless communications, semiconductors, and advanced electronic components, systems, and services, takes an approach to knowledge management that conforms to the hybrid model. Motorola’s major business segments/sectors are the personal communication segment (PCS), network systems segment (NSS), commercial government and industrial systems segment (CGISS), semiconductor products segment (SPS), and other product segment (OPS). Motorola has an internal portal where knowledge objects (from and about projects) are stored in a central location for employee access and use across sectors. Examples of these documents include white papers, feature requirements documents, project test reports, and data reports. These documents are posted for the software/hardware features for a given product in a sector.
Each employee can customize a portion of the portal, thus fostering the P2P approach. Functionality exists for storing their documents on the central repository with password-protected locations for confidentiality purposes. Passwords are issued by the owner (knowledge provider and document author) of the site, so if an individual first accesses the site he or she will be instructed to “contact the site owner/administrator for password.” This guarantees that the material is not openly available and people trying to access it have a conversation with the original source or owner of the material knowledge, just like a P2P exchange. Search functionalities allow employees to locate knowledge sources; however, a full-fledged indexing system is not present. Thus, Motorola follows a hybrid approach to knowledge management much like the one proposed here.
Managing Distributed Teams
Web Methods development across distributed teams offers many benefits but also introduces significant challenges. Some research indicates that more than 90% of communication effectiveness is determined by non-verbal cues. Communications between teams in multiple locations and multiple time zones can be challenging because in person discussions are often replaced by telephone calls and written communications. Language and cultural differences provide additional opportunities for misunderstandings. Team members also do not have the opportunity to “see” their coworkers at work and thus do not always have good visibility into what they’re delivering. The resulting misunderstandings coupled with a lack of visibility can lead to mistrust between coworkers limiting the productivity of the entire team. TEAM Server helps bridge that gap by increasing both visibility and accountability.
There are two basic ways to distribute web Methods projects across multiple teams. One is to distribute the effort across teams performing the same function (like Development or Testing) and another is to assign functional teams to a specific location.
Distributed Functional Teams
For example, let’s say your project’s development team is distributed across 2 or more regions. How do you hand off development artifacts between developers? How do developers tell each other exactly how far they got? And how do they tell each other what changes were made to the program logic?
TEAM Server gives team members the ability to manage multiple lines of code, track all changes to the program logic, and see exactly what changes are applied by each developer. This added level of visibility minimizes miscommunication and allows all developer to see exactly what changes other developers are making to the project.
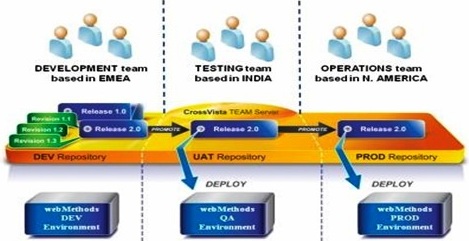
Distributed Teams Organized By Function
A tightly managed and automated application development process allows distributed teams to work more confidently. TEAM Server provides a framework upon which automated processes can be built.
• Development teams can very easily hand off new builds to the QA team.
• QA teams can use promotion rules to automatically reconfigure the build for deployment to the QA environment. They can also use TEAM Server to verify that, with the exception of the new code, the current QA environment is a mirror image of the Prod Environment.
• The Administrators within the Operations team will have the same abilities as the QA team. In addition, all actions will be audited so Administrators will be able to know who, when, and what changes have been made to any of the environments.1.) Software development lends itself well to distribution of tasks.
The question then becomes why distribute your software development? There are a number of reasons, two of which are primary:
• High quality talent is not always local
• Isolation works - cannot get "do not disturb" around the office, and this is a real important issue. There are references given that for example one phone call to a developer will make them take 10-15 mins to get back on track.
2) How do I mitigate / manage risk in a distributed project?There are a number of answers to this since there are actually a number of types of risk to mitigate:
• How do I communicate effectively communicate over large distances?
• How do I cope with giving up control (not micromanaging by having to have everyone right there)?
• How can I tell if someone is thrashing from a distance?
Basically, you can and will lose control of developers even if they are collocated. The trick is to be able to identify it, with local or remote staff. Thrashing is when a developer gets stuck and will not ask for help. This can happen even in a cube, and for weeks at a time, so this is not new even with remote staff. The issue is again how to identify it.
The solution to these comes down to using Scrum as your project management methodology, and this will assist in identifying these issues. Through this you gain control over you’re through empowerment and even if they are not right there.Which also leads to the question of isn’t it important to have face to face interaction? Well, it is to an extent. As mentioned later it is important to make sure that most people know each other by face having had some type of in person interaction so that you can “see” the person that is remote, meaning that you can get a read on what that person is saying between the lines. Several techniques for how to do this are given later. Also, stress that communications by e-mail for important items is not the most effective means of getting things done. Stress using phone, Skype, web cams, or getting in person if possible.
3) Distribute software development leads to greater agility.
This is true when combined with Scrum and short cycles / iterations. Doing this can lead to very quick releases when properly defined. This is actually a large topic to discuss that I will elaborate on independently in another post.
4) Use available tools to assist in managing the distributed agile process.
There are a number of tools available to minimize distance between team members:
• Scrum: Methodology for collaboration and identifying / assigning work.
• TFS / scrum: Tools for running Scrum in a distribute manner.
• Skype: for communicating amongst the team with low cost.
And make sure that the Scrum Master ensures that everyone uses them and collaborates daily through the daily Scrum.5) Identifying and addressing “Thrashing” with remote members.
• How can thrashing be identified over Skype? This basically comes down to being able to ask a simple question: “Why are you working for so long on this?” If you then you get a long answer, basically a laundry list of seemingly unrelated statements to the problem at hand, then they have probably tried lots of things except asking for help.
• Also, if you run one week sprints, you don't have to care too much about thrashing as long as the work is done at the end of the sprint. If it is not done at that time, then you are never more than one week behind and you can then identify those people who need help through the lack of a deliverable.
• It is also important to start with several small architectural sprints (and put these in the wiki - my input). These can be used to define a baseline for how the system should be implemented and reviewed against.6) How to perform Scrums with remote people?
• Keep iterations short, perhaps just one to two weeks. This will ensure that thrashing does not exceed more than one iteration.
• Use TFS with scrum feature to manage the work items in the iteration and allow all remote team members to collaborate.
• Extensively utilize Skype as well as plug-ins for white boarding and sharing. Skype cast daily and make sure you go around the horn and use PTI (pardon the interruption - time is up).
• Prevent “hiders” in the Scrums by making sure that Scrum Masters make sure everyone participates.
• Be diligent to make sure that Scrums do not devolve into status meetings; remember that they are for solving issues and giving marching orders.
• What's the effective size of a scrum - 10 people, then do scrum of scrums7) Team collaboration
What techniques are there to build collaboration amongst the remote workers?
• Kick off the project in person with everyone present no matter the cost as it will be saved later and it will allow distributed people to get to know each other
• Explain the business in the kick off, as developers will need to understand this to work independently, and may also likely take control of business features through the Scrum process
• Get developers to think as a user, having them always think in the frame of reference of a user operating the system.
• Empower the developer to make decisions as it will mitigate thrashing, and make them feel free to ask for input on the next sprint while working on the current one.
8) How to keep remote developers feeling as though they are part of the team?
The problem(s) here are:
• How to keep remote staff happy and motivated
• How to keep remote staff feeling that they are a part of the team
Solutions are:
• Operate with a staff augmentation model
• Engage with local recruiters to find what local talent you can
• Do a staff rotation model, were every person in a particular office should within a 2 year timeframe work in other offices for extended periods (2-4 weeks), and always have one person from every office in another office to build true relationships.
• These techniques will also let you get to know the people so you can understand them in the e-mail
9) How about dealing with the cultural differences?
• It’s Stephen’s opinion that the younger generation is much more liberal and technology has transcended the cultural borders therefore mitigating those issues.
10) In General:
• It seems as scrum master merges with product manager a lot. This is something that I was aware of from experience, but it was nice to hear Stephen express it too.
• Stephen had a great example of how to use current tools to manage a crisis. A remote worker said he had a power outage. Stephen used google earth and local search to find him an Internet cafe to go work at.
• Carl asked if it would be possible to use second life for remote interaction? I kind of like this idea and may look into it.
• Richard feels that he can handle only a maximum of 0.25 interruptions per hour (2 per 8hr work day).Problem in successful distribution:
Distributed projects create unusual challenges since the project team members are not collocated (not physically together). As a result, the following issues can become impediments to the success of a project.
• Lack of trust between the geographically dispersed teams.
• Unwieldy amounts of time spent on communication.
• Inability to foster a “one-team” feeling due to cultural differences.
• Lack of participation from team members during common meetings.
• Lack of identity with the project team, as team members in different geographies may speak different languages and/or have different project practices.
These stumbling blocks have become nightmares for many software project managers facilitating distributed projects. Here are few to-dos to add to your communication arsenal if you are assigned to manage a distributed project.
• Find and document the overlap time between different geographically distributed teams (don't forget Daylight Savings Time).
• Publish the Instant Messaging (IM) addresses of all the team members (and the best time to reach them).
• Make sure that each key stakeholder has access to all conference call access details (Web and Telephone).
• Gather and share the vacation details for different teams on a shared calendar.
• Publish a schedule of daily stand-up meeting between geographically dispersed teams. Stand-up meetings are better than sit-down ones. Attendees focus, because no one wants to stand for a long time.
• Publish the name and a headshot (photo) of each team member. Identify a back-up contact person for each key role.
• Set up a common location for sharing project artifacts between the teams (documents/reports/templates).
Besides enhancing your communication strategy, there are logistics issues that need to be addressed to promote superior communication among distributed teams.
• Invest in high-quality speakerphones for all locations. When participating in conference calls, assurances of stable phone connectivity between different teams will go a long way to building camaraderie between those teams participating.
• Place the phone in a big enough room for the team members to gather comfortably for a call. Equip the room with a large table, as you may want to provide food for those participants meeting at unusual hours. Add white boards, so notes from phone conversations can be jotted down quickly in a way everyone in the room can view.
• Budget funds for a few team members to travel to other team sites, perhaps during the Initiation Phase or while planning Quality Assurance processes.
• Create a project dashboard (use any collaboration tool) for teams to communicate their issues. Share these dashboard images between the teams whether they use online tools, or only have the technology for digital photo sharing.
• Publish the overall goals and targets of the project at a common location for everyone to see, even telecommuting team members working from home.
• Arrange presentations by business sponsors and insist key teams members from every location participate in hearing these presentations.
As virtual and distributed teams become more common, you can increase your chances of success with innovative communication techniques.References:
—http://www.me2team.com/MoreInformation/Papers/WhitePapers/ManagingProjects/tabid/164/Default.aspx.
—http://www.projectperfect.com.au/info_managing_offshore_projects_1.php.
—http://www.google.co.in

DOWNLOAD
FREE TERM PAPER »
» » 